Tag: OpenStreetMap
-

From Planet File to Vector Tiles: Benchmarking My OpenStreetMap Processing Pipeline
TL;DR: I benchmarked my OpenStreetMap processing pipeline (Osmosis → Osmium → Tilemaker) across four machines. Updating the planet takes ~16–21 minutes, while generating worldwide vector tiles (z14) takes between 1h45 and 6h18 depending on hardware and parameters. With tuned Tilemaker parameters and sufficient RAM I was able to reduce tile generation to ~1h45. The Full…
-
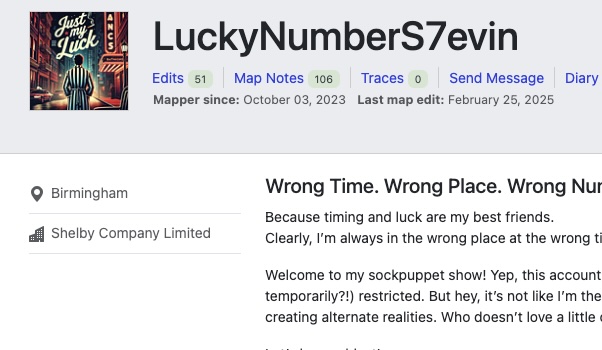
Who and Where? Analyzing the New Company and Location Fields in OpenStreetMap Profiles
In May 2025, the OpenStreetMap (OSM) website introduced two optional fields in public user profiles: company and location (see Github). Both fields accept unstructured free text and are not validated in any way. Since these fields are publicly visible, I wondered whether they could be useful for my “How Did You Contribute to OpenStreetMap?” (HDYC)…
-

Data Science für soziale Innovation? RLP NEXT
Am Montag, den 6. Oktober, durfte ich beim RLP NEXT Innovationkongress in Mainz einen Vortrag mit dem Titel „Data Science für soziale Innovation?“ halten. Im Gepäck hatte ich fünf kurze Geschichten aus der Landeshauptstadt des Landes Rheinland-Pfalz – rund um Open Data, Künstliche Intelligenz und nachhaltige Stadtentwicklung. Mein Hauptziel: dem Publikum auf der Innovation Stage…
-

OpenData vom Bundesamt für Kartographie und Geodäsie vs. Crowdsourced OpenStreetMap in Deutschland – Ein Vergleich Offener Daten
Nach knapp 1.000 Tagen Abstinenz (endlich?) mal wieder ein Blog Post von mir. Aufgrund des inhaltlichen und räumlichen Bezugs diesmal auf deutsch. Ein „offizieller offener“ Datensatz von einer Bundesbehörde? Gut, wie sieht’s im Vergleich zu gemeinsam zusammengetragen Daten aus, z.B. OpenStreetMap? Lassen sich Unterschiede in der Qualität feststellen? Sind die Datensätze womöglich auf Augenhöhe oder…
-
#100 – Thank you!
While I was working on my latest blog post, I realized that I had already written 100 posts over the past nine years. All posts have one thing in common: They are about the well-known and maybe never ending OpenStreetMap project …
-
Additional insights about OSM changeset discussions: Who requests, receives and responds?
Last year I wrote two blog posts about the OpenStreetMap (OSM) feature that allows commenting on contributor map changes within a changeset. The first blog post showed some general descriptive statistics about the number of created changeset discussions …
-
Counting changes per Country – A different approach
OSMstats contains several statistics about the OpenStreetMap (OSM) project, such as daily-created objects, the amount of active contributors or detailed numbers for individual countries. One way to determine the sum of created or modified Node objects, is to use …
-
Add a Note in OSM … Stats & Personal Profiles
Since April 23th, 2013 each visitor, user or contributor of the OpenStreetMap project can “add a note” to the map in order to easily mark an error or missing object in the map data. You can find more information about this new feature in the OSM wiki. It is a great new way for people…